In recent years, the development of embodied intelligence has attracted widespread attention. It is crucial to develop high-energy-efficiency perception-computation integrated large model edge-side inference chips to achieve the local deployment of multimodal large models.
Professor Hao Yu’s research team from the School of Microelectronics (SME) at the Southern University of Science and Technology (SUSTech) has made advances in embodied intelligence for large language and vision models. Their breakthroughs in embodied intelligent chips, embodied intelligent accelerator cards, and embodied intelligent systems provide core AI chip technologies to advance China’s transition from information intelligence to physical and biological intelligence. They have made a series of research advancements and published three papers in international journals, including the Journal of Solid-State Circuits, IEEE Transactions on Circuits and Systems I: Regular Papers, and IEEE Integrated Circuits and Systems.

Embodied intelligent chips
As the era of large models unfolds, the computational demands of deep neural networks are growing exponentially. Traditional chip architectures, however, face dual bottlenecks in energy efficiency and performance. To overcome these challenges, the researchers explored a cube-systolic architecture optimized for embodied deep-learning networks. Through network search optimization, the architecture achieved a state-of-the-art energy efficiency of 29.12 TOPS/W and an area efficiency of 7.94 TOPS/mm². These breakthroughs were made possible by addressing the “energy-area-flexibility” trilemma in traditional AI chip design through three key innovations: dynamic precision adjustment, structured sparse encoding, and a vectorized systolic array.
The dynamic precision adjustment balances energy efficiency and accuracy by dynamically optimizing computational precision, while the structured sparse encoding improves compression rates by 30% without sacrificing model accuracy. The vectorized systolic array, an innovative architecture, boosts memory bandwidth utilization to 92%, drastically reducing data movement energy.
Their research findings, entitled “A 29.12 TOPS/W Vector Systolic Accelerator with NAS-optimized DNNs in 28-nm CMOS”, have been accepted in the top-tier journal IEEE Journal of Solid-State Circuits.
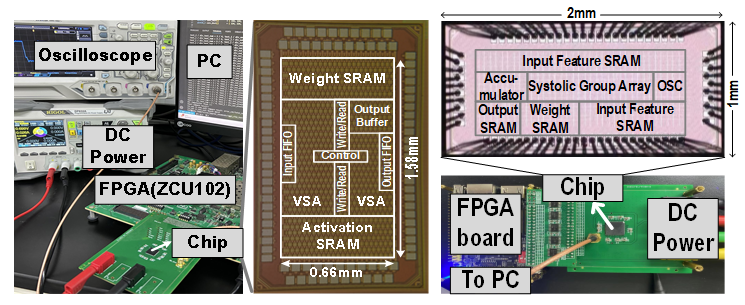
Figure 1. Hybrid-precision accelerator chip and hybrid-sparsity accelerator chip
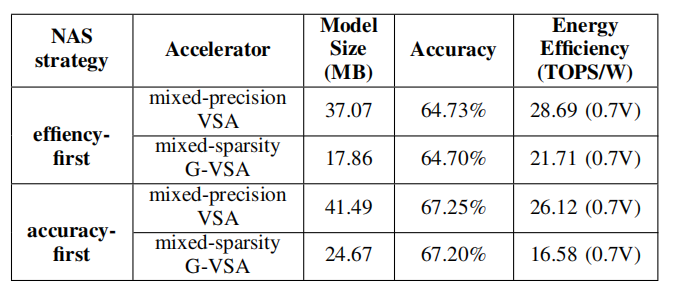
Figure 2. Performance comparison of the cube-systolic architecture chip with hybrid precision and sparsity
Ph.D. student Kai Li from SME at SUSTech is the first author of this paper. Professor Hao Yu is the corresponding author, and SUSTech is the first affiliation.
Embodied intelligent accelerator cards
The team designed an edge-side large model inference card based on the cube-systolic architecture, enabling efficient deployment of large language models (LLMs) at the edge with 75% bandwidth utilization (75 tps) and further overcame challenges in deploying LLMs on resource-constrained edge devices Multiple 7B-parameter LLMs and multimodal models were successfully deployed on the system. Compared to GPUs, the system achieves 1.91 times higher throughput and 7.55 times better energy efficiency. It also outperforms the state-of-the-art FPGA accelerator, FlightLLM, by 10–24% in overall performance.
Their research findings, entitled “EdgeLLM: A Highly Efficient CPU-FPGA Heterogeneous Edge Accelerator for Large Language Models”, have been published in IEEE Transactions on Circuits and Systems I: Regular Papers.
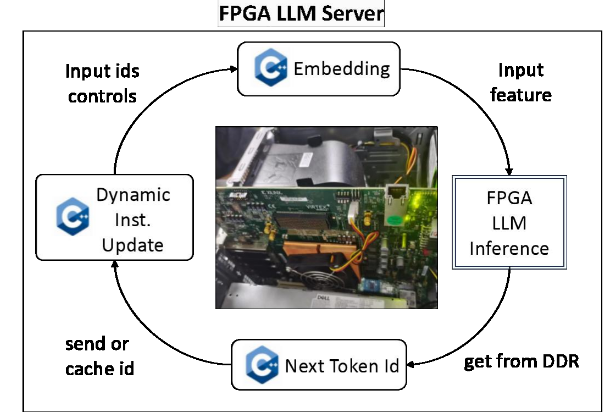
Figure 3. Embodied intelligent accelerator cards
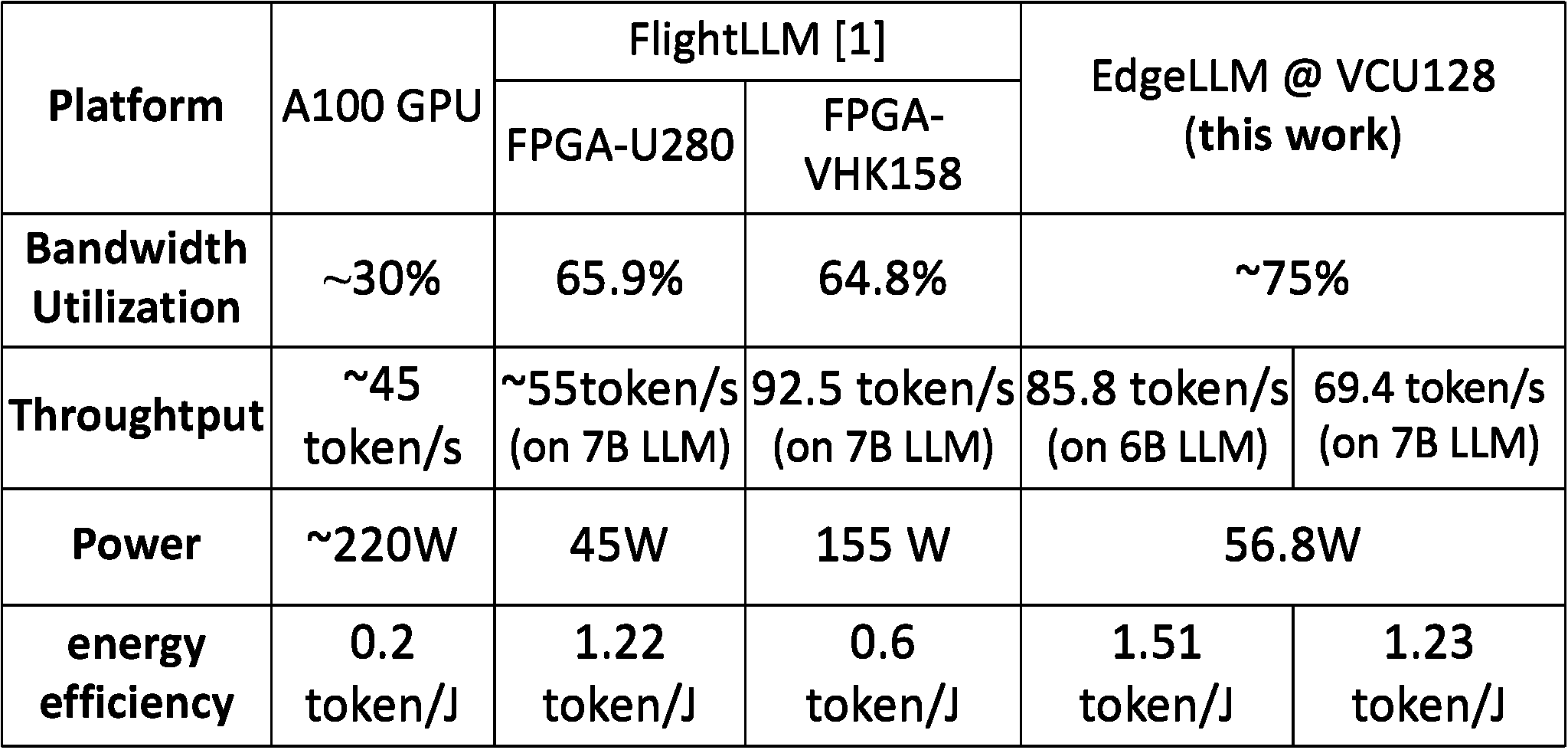
Figure 4. Comparison of embodied intelligent accelerator cards
Master’s student Ao Shen from SME at SUSTech and Researcher Mingqiang Huang from the Shenzhen Institutes of Advanced Technology, Chinese Academy of Sciences (SIAT, CAS) are the co-first authors of this paper. Professor Hao Yu is the corresponding author, and SUSTech is the first affiliation.
Embodied intelligent system
In collaboration with Genesense Technology Inc., the researchers developed the emGene LLM-embodied NGS sequencer, which deploys optimized LLMs on edge-side accelerator cards. This enables real-time, on-site DNA analysis, revolutionizing intelligent genetic diagnosis in healthcare.
Their research findings, entitled “emGene: An Embodied LLM NGS Sequencer for Real-time Precision Diagnostics”, have been published in IEEE Integrated Circuits and Systems.
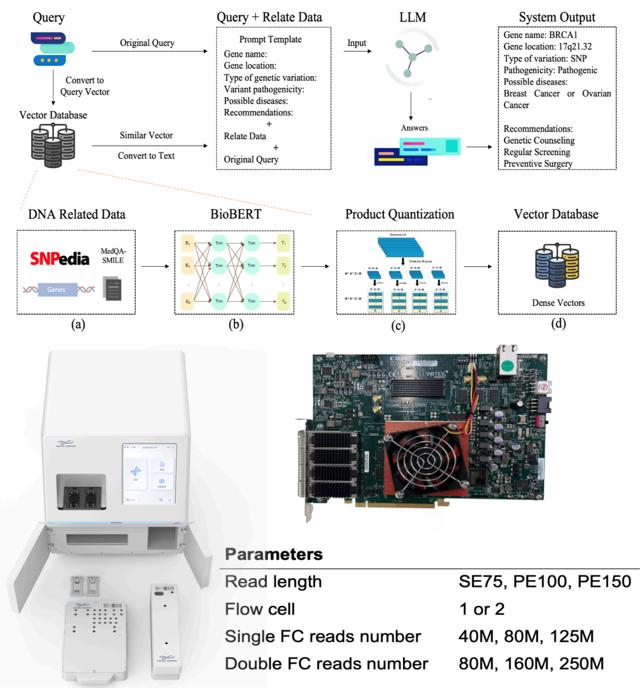
Figure 5. emGene LLM-embodied edge NGS sequencer
Professor Hao Yu is the corresponding author of this paper, and SUSTech is the first affiliation.
Paper links (In order of appearance above):
IEEE Journal of Solid-State Circuits: https://ieeexplore.ieee.org/document/10972309
IEEE Transactions on Circuits and Systems I: Regular Papers: https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=10916480
IEEE Integrated Circuits and Systems: https://ieeexplore.ieee.org/document/10930726
To read all stories about SUSTech science, subscribe to the monthly SUSTech Newsletter.
Proofread ByAdrian Cremin, Yuwen ZENG
Photo ByYan QIU






