The biggest challenge of the digital economy is how to build low-carbon computing infrastructure, and one of its key technologies is how to design energy-efficient edge-computing chips.

Professor Hao Yu from the School of Microelectronics at the Southern University of Science and Technology (SUSTech) led a team of researchers, which included Research Associate Professor Wei Mao and doctoral students Kai Li and Dingbang Liu, to focus on edge-computing integrated circuit design, forming a series of IPs and achieving a number of internationally leading research results.
Professor Yu’s team has published many scientific research papers in top journals in the field of integrated circuit design. Their research results are of great significance for breaking through the compute-bound and power-bound of chip in the “post-Moore era”.
In the direction of edge-computing, the team proposed a multi-precision deep learning chip, which can achieve up to 40.69TOPS/W energy efficiency under the 28 nm CMOS process through network architecture search (NAS) optimization.
The relevant results, entitled “An Energy-Efficient Mixed-Bitwidth Systolic Accelerator for NAS-Optimized Deep Neural Networks,” were published in IEEE Transactions on Very Large Scale Integration (VLSI) Systems.
Research Assoc. Prof. Wei Mao is the first author of the paper. Prof. Hao Yu is the corresponding author, and SUSTech is the first affiliation. This work was supported by the National Natural Science Foundation of China Key Program.
At the same time, combined with the structured sparse and vector systolic architecture, the performance of up to 2863.29 GOPS can be achieved on the FPGA platform. These results, entitled “A High Performance Multi-Bit-Width Booth Vector Systolic Accelerator for NAS Optimized Deep Learning Neural Networks,” were published in IEEE Transactions on Circuits and Systems I.
Assoc. Prof. Mingqiang Huang, a visiting scholar at SUSTech, is the first author of this paper. Prof. Hao Yu is the corresponding author, and SUSTech is the first affiliation. This work was supported by the National Natural Science Foundation of China Key Program.
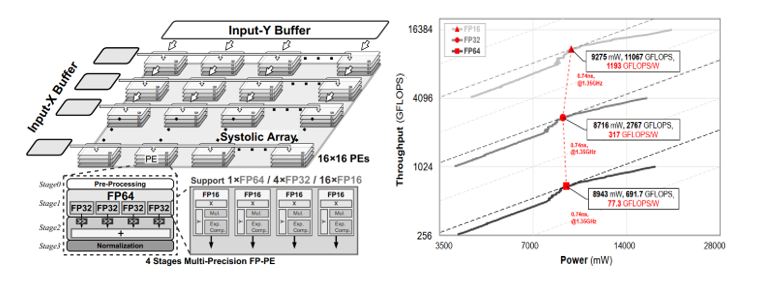
Figure 1. Mixed-precision AI chips for edge computing
In the direction of high-performance computing, the proposed system can support half-precision FP16 to double-precision FP64, realize precision fusion, and have efficient data computing based on multi-precision parallel processing units. In addition, the team proposed an analysis method based on minimum redundant hardware and redundant operations for optimization implementation with maximum hardware utilization.
The relevant results, entitled “A Vector Systolic Accelerator for Multi-Precision Floating-Point High-Performance Computing,” were published in the IEEE Transactions on Very Large Scale Integration (VLSI) Systems, a well-known journal covering system specification, design and partitioning, system-level test, and reliable VLSI/ULSI systems.
Research Assoc. Prof. Wei Mao is the first author of this paper. Prof. Hao Yu is the corresponding author, and SUSTech is the first affiliation. The work was supported by the Peacock Team Project of Shenzhen High-level Talents.
Through the vector pulsation accelerator system architecture, the data reuse rate and data transmission efficiency were improved. Under the 28 nm CMOS process, the clock frequency can reach 1.351GHz for high-performance computing and artificial intelligence algorithm applications, and energy efficiency of up to 1193GLOPS/W can be achieved.
These results, entitled “A Configurable Floating-Point Multiple-Precision Processing Element for HPC and AI Converged Computing,” were published in IEEE Transactions on Circuits and Systems II.
Kai Li, a 2021 doctoral student at SUSTech, is the first author of this paper. Profs. Hao Yu and Wei Mao are the co-corresponding authors, and SUSTech is the first affiliation. This work was supported by the National Natural Science Foundation of China Key Program.
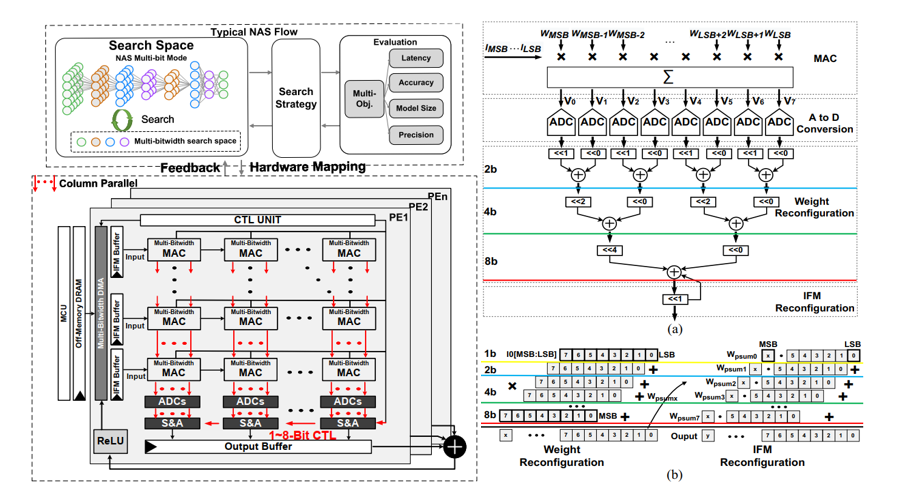
Figure 2. Floating-point multi-precision vector systolic accelerator for HPC+AI
In the direction of the Computing-In-Memory (CIM) based on a resistive memory device (ReRAM), the team focused on the foundation problems widely existing in conventional ReRAM and CIM. This included big unit parameter mismatch, low parallelism in row and column operations, as well as the large power consumption of supporting circuits.
The team proposed the design scheme of proportional resistance saturation amplification, charge accumulation output, and circuit optimization based on network characteristics to realize a fully parallel multi-precision and energy-efficient CIM accelerator with sparse network optimization. The accelerator achieves an average energy efficiency of 479.37TOPS/W for the NAS-optimized ResNet-18 network.
Their results, entitled “An Energy-Efficient Mixed-Bit CNN Accelerator with Column Parallel Readout for ReRAM-based In-memory Computing,” were published in the IEEE Journal on Emerging and Selected Topics in Circuits and Systems.
Dingbang Liu, a 2020 doctoral student at SUSTech, is the first author of this paper. Profs. Hao Yu and Wei Mao are the co-corresponding authors, and SUSTech is the first affiliation. This work was supported by the National Key Technologies R&D Program of the Ministry of Science and Technology.
Figure 3. High-throughput and energy-efficient all-parallel integrated CIM array
Prof. Hao Yu also issued an English book, “ReRAM-based Machine Learning,” which was published by the British Institute of Engineering and Technology (IET). This monograph mainly reviews the latest research progress of in-memory computing based on a memristor (ReRAM).
The monograph first introduces the memristor device model and simulation method, then designs a logic circuit based on the memristor device. It also proposes a memristor accelerator design suitable for distributed computing in memory-computing architecture and a binarized machine learning algorithm ideal for memristor accelerator computing. In addition, the specific large-scale deep neural network (ResNet) computing model and mapping methods for the memristor accelerator are given. It gives a specific reference route for the future paradigm of memristor computing. This book enriches the students in microelectronics, and is also an important reference for researchers engaged in the field of computing to understand modern AI hardware design-related devices, systems, and algorithms.

Figure 4. IET Book, ReRAM-based Machine Learning
Paper links (In order of appearance above):
IEEE Transactions on Very Large Scale Integration (VLSI) Systems: https://ieeexplore.ieee.org/document/9920733
IEEE Transactions on Circuits and Systems I: https://ieeexplore.ieee.org/document/9793397
IEEE Transactions on Very Large Scale Integration (VLSI) Systems: https://ieeexplore.ieee.org/document/9795894
IEEE Transactions on Circuits and Systems II: https://ieeexplore.ieee.org/document/9631952
IEEE Journal on Emerging and Selected Topics in Circuits and Systems: https://ieeexplore.ieee.org/document/9911654
To read all stories about SUSTech science, subscribe to the monthly SUSTech Newsletter.
Proofread ByAdrian Cremin, Yingying XIA
Photo By






