在近日于北京召开的2019年国际软件测试与分析大会(ISSTA 2019) 上,我校计算机科学与工程系助理教授张煜群团队发表的关于深度学习用于软件错误定位的研究论文“DeepFL:Integrating Multiple Fault Diagnosis Dimensions for Deep Fault Localization”获得大会最佳论文奖。

ISSTA 2019大会最佳论文奖(ACM SIGSOFT Distinguished Paper Award)
“错误定位(Fault localization)”即为软件程序代码中的程序实体(program entity)按照出错的可能性排序,从而提高工程师寻找并解决程序错误的效率。由于软件错误的不可避免性,错误定位是软件工程领域经久不衰的热点之一。
研究团队采用了多种不同维度的错误定位方法,用这些方法为每个程序实体赋予了不同维度的特征;同时还提出了分级深度学习模型,充分学习每个程序实体的数百特征中的隐藏信息并获得各个程序实体的出错可能排序结果。
此前的相关研究工作普遍采用参考单维度或双维度特征的工作方法,而团队此次的研究则突破性地采用了参考多维度工作方法。这些多维度特征具体包括四大项:1.程序实体的覆盖信息(coverage information),即程序实体在运行失败或成功的测试用例中是否被覆盖到的信息,一般来说被失败测试用例覆盖越多的程序实体更有出错的可能性;2. 程序变异信息(mutation information), 即当原程序被改变形成的变异体(mutant)运行结果也发生改变时程序实体的覆盖信息,一般来说变异体导致运行结果出错时,其所在的程序实体更容易出错;3. 复杂度信息,越复杂的程序实体越有出错可能;4. 相似度信息,即程序实体与训练集中被标注为错误程序实体的相似性,越相似便越有出错的可能性。
论文的另一个亮点在于团队对经典的深度学习模型进行了改造优化。相较于传统的多层感知器和循环神经网络(Recurrent Neural Networks),团队提出的分级深度学习模型则是将不同维度特征独立分开,充分挖掘了同一维度下特征的隐藏信息。同时,团队提出的分级模型也充分考虑了不同维度特征间存在的语义颗粒度关系,覆盖信息与变换信息的关联度相比于另外两种传统模型更高。
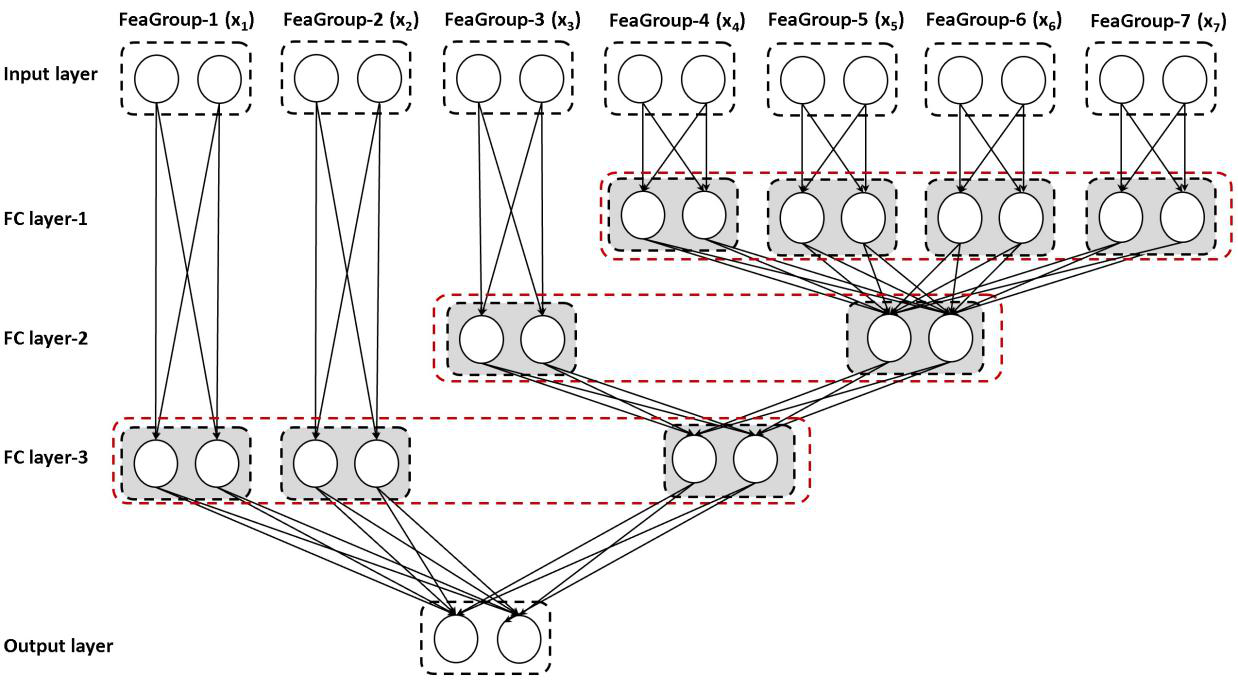
分级深度学习模型
团队提出的基于深度学习的错误定位方法在公认的五大指标(Top1,Top3,Top5,MFR,MAR)上都优于之前相关领域已提出的其它方法,尤其最重要的Top1指标(错误程序实体位于排序结果第一位)比此前效果最好的方法提高了30%。同时,该方法在跨软件项目实验中也展现了很好的效果,耗时仅为其它方法的千分之一,具有一定的应用前景。
ACM ISSTA是软件工程领域公认的顶尖学术会议,被CCF(中国计算机学会)列为A类会议。该论文由德克萨斯州大学计算机系助理教授张令明与张煜群合作发表,第一作者为德克萨斯大学博士生李夏,第二作者为南科大计算机系科研助理李巍。
论文链接:
https://dl.acm.org/citation.cfm?id=3330574
供稿:计算机科学与工程系





南方科技大学微信

南方科技大学视频号

南方科技大学抖音号

南方科技大学快手号

南方科技大学头条号

南方科技大学南方+